

That’s since Google can usually find and index all of the significant pages on your site.
And they’ll routinely NOT index pages that aren’t significant or duplicate versions of other pages.
That supposed, there are 3 main reasons that you’d want to use a robots.txt file.
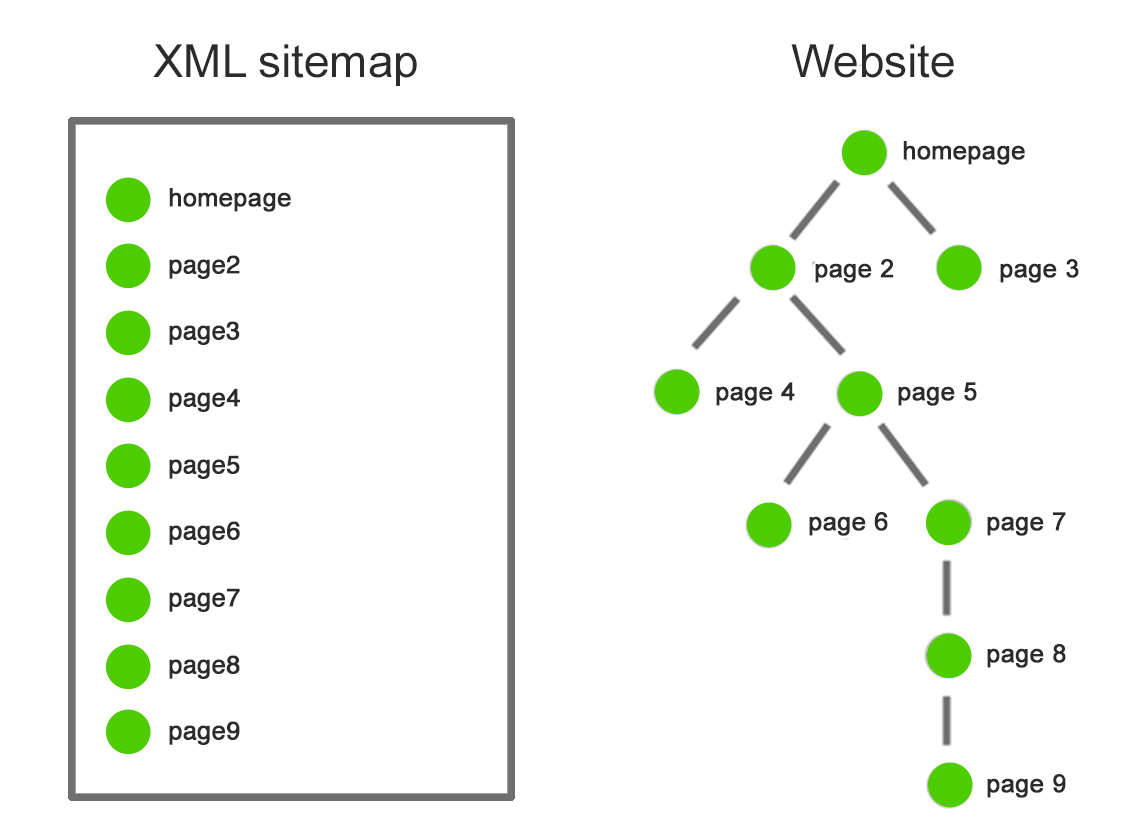
Sometimes you consume pages on your website that you don’t poverty indexed. For instance, you might have a performance version of a page. Or a login page. These pages need to exist. But you don’t want chance people mooring on them. This is a case anywhere you’d use robots.txt to block these sheets from search engine crawlers and bots.
Maximize Crawl Budget: If you’re consuming a tough time receiving all of your pages indexed, you might have a crawl budget problematic. By blocking insignificant pages with robots.txt, Googlebot can devote additional of your crawl inexpensive on the pages that really material.
Prevent Indexing of Resources: Using meta orders can work just as well as Robots.txt for stopping pages from receiving indexed. However, meta orders don’t work well for hypermedia resources, like PDFs and images. That’s anywhere robots.txt comes into play.
The bottom line? Robots.txt tells search engine spiders not to crawl exact pages on your website.
If the number competitions the number of pages that you want indexed, you don’t need to trouble with a Robots.txt file.
But if that number is advanced than you predictable (and you notice indexed URLs that shouldn’t be indexed), then it’s time to make a robots.txt file for your website.
Related Post
When it comes to SEO, there are over hundreds of Google ranking issues you need to principal as well as perform them in order to upsurge your search
CONTINUE READINGOpen Graph is an net procedure that was initially shaped by Facebook to regulate the use of metadata within a webpage to signify the content of a pag
CONTINUE READINGA favicon is a small 16×16-pixel image that serves as marking for your site. Its main drive is to help companies find your page calmer when they hav
CONTINUE READINGCSS minification is the procedure of eliminating extra code from CSS basis files, with the goal of plummeting file size without altering how the CSS
CONTINUE READINGIn adding, Atomic Habits has been interpreted into additional than 50 languages. It is often amongst the top 10 best-selling records in major global
CONTINUE READING
Hello! I am Srikanth Giddalur
Continue ReadingSearch
Choose Categories

Archives
Popular Post

Declining Organic Traffic Got You Down?
09 May, 2024Google Demand Gen advertisers get generative image tools
27 April, 2024Video and SEO: A Match Made in Rankings Heaven?
27 April, 2024How Can I Find Relevant Keywords?
27 April, 2024
Tags

Comments